This is the second of four blog posts on the development process of the {stacks} package, excerpted from my Reed senior thesis project Tidy Model Stacking with R.
Part 1: Introduction
Part 3: Naming Things
Part 4: Big Things
Undoubtedly, one of the most challenging parts of developing {stacks} was determining what working with the package should “feel” like. The foremost challenge here is striking a balance between ease of use and statistical expressiveness. On one end of this spectrum, the package could encompass its operations within one function, accommodating many input types and obscuring statistical complexities for the benefit of code conciseness. On the other, each requisite statistical operation could require explicit code and only accommodate input types reflecting an opinionated statistical practice.
While the latter end of this spectrum is a bit harder to conceptualize, and feels more ridiculous at its extremes, implementations closer to the former are rather common. How “magical” could the functionality in this package be? What does “model stacking made easy” look like? Perhaps the clearest illustration of the benefits of {stacks}’ approach—an initialization function and three “core verbs”—is to begin with an approach on the more magical end of this spectrum. Considering such an approach, I’ll identify some of the more major drawbacks to user understanding and the intermediate operations that are made inaccessible. Then, I’ll uncouple operations that thus ought to be distinct, iterating on this “conscious uncoupling” process until I’ve arrived at a happy medium between conciseness and verbosity (Bryan, 2019). I use the word “syntax” to refer a set of functions, grouping some set of operations in more or less coarse grammars, that could encapsulate the functionality of a model ensembling package. For example, the syntax ultimately implemented in the package consists of stacks, add_candidates, blend_predictions, and fit_members. Generally, discussion of the names of these functions will be left to the next blog post.
Super auto ML AI magic
To start, then, we’ll consider one function—we can call it stack_models—that simply calls the current core verbs in succession. Its definition might look something like the following. (This code is for the purpose of illustration only, and does not work as presented. See the workflow_set S3 method of add_candidates for an iterated implementation of add_candidates that could be utilized in this kind of construction.)
# initializes a data stack, adds all candidate members,
# fits the meta-learner on their predictions, and then
# fits all members with non-zero stacking coefficients
stack_models <- function(...) {
stacks() %>%
purrr::reduce(
...,
add_candidates
) %>%
blend_predictions() %>%
fit_members()
}The purrr::reduce construction here iteratively passes each element of ..., a sequence of model definitions, to add_candidates.
The process of fitting an ensemble model with this code would be quite concise, to say the least. With the necessary model definitions created—say model1 and model2—the API would present as such.
# fit an ensemble model with model1 and model2
stack_models(
model1,
model2
)What sacrifice does this kind of abstraction implicate?
To begin answering this question, we’ll start with the obfuscation of what were ultimately the last two core verbs of the package—blend_predictions and fit_members. The blend_predictions function fits the meta-learner (an elastic net model) on the predictions from each candidate member, determining how to best combine their outputs. Candidate members with non-zero meta-learner coefficients are model stack members, and need to be trained on the full training set rather than the resamples used to construct the data stack.
In some cases, though, the step of training a member on the full training set is substantially more computationally intensive than training the analogous candidate on the resampled data used to construct the data stack.
More concretely, consider a \(10\)-fold cross-validation resampling scheme. The training data is partitioned into \(10\) folds of equal size. Then, the candidate model configuration is trained on \(9\) of the folds, producing \(9\) resampled models. Each of these resampled models then predicts the values for the \(10\)th fold—the validation set, or partition of the training folds used for model validation—and {stacks} summarizes those models’ predictions, forming that candidates’ predictions for the validation set.
Note that each of these \(9\) models is trained on a dataset with cardinality equal to a tenth of the cardinality of the full training set. The computational complexity of the training step for many statistical models is “worse” than linear as a function of the cardinality of the dataset; that is, training some statistical models on a dataset with \(100\) rows takes much more than \(10\) times as long to train that same model on a dataset with \(10\) rows.
Consider, for instance, a thin-plate spline model. The time to fit this model is proportional to the cube of the cardinality of the training set (Hastie, 2009). In our example, then, training on the \(10\)-row training set takes \(10^3\) time units, and training on the \(100\)-row training set takes \(100^3 = 10^6\) time units. Thus, training on the full \(100\)-row training set takes \(10^6/10^3 = 1,000\) times as long as training on the \(10\)-row fold of the training set. Thus, training this model on our full \(100\)-row training set would take over \(100\) times as long as training \(9\) models on the resampled \(10\)-row folds and summarizing their outputs.
Other examples of models that scale “worse” than linearly include many varieties of neural networks, K-nearest neighbors, and other discriminant analysis techniques like support vector machines (Hastie, 2009).
In the context of {stacks}, this recognition of differences in runtime is crucial. After fitting the meta-learner on the candidates, one can evaluate the degree of penalization chosen and its effect on member selection. If the practitioner specifies a very small penalty, or the grid search specified results in a very small penalty, then most all of the candidate members will need to be fitted—a sometimes profoundly computationally intensive task. Delineating between the steps of training the meta-learner and then training the candidate members that it “selects” gives the practitioner a chance to evaluate her chosen degree of regularization and its impact on model selection. A critical choice of penalty value can often result in a much more parsimonious (and realistically trainable) set of selected member models, saving the practitioner valuable computing time.
Minimally, then, the package ought to delineate between these two training steps.
Twenty four karat magic in the air
Instead, consider an approach that includes two functions: one that adds a set of candidate members and fits a meta-learner to them, and another that fits the candidates with non-zero stacking coefficients on the full training sets. That approach might look something like this:
# initializes a data stack, adds all candidate members,
# and fits the meta-learner on their predictions
prepare_stack <- function(...) {
stacks() %>%
purrr::reduce(
...,
add_candidates
) %>%
blend_predictions()
}
# the current fit_members function is left as is
fit_members <- fit_membersThe process of fitting an ensemble model with this approach would be still be a good bit more concise than the current syntax. This approach, as well, gives the practitioner a moment to consider the computational implications of the chosen penalty before fitting members on the full training set. With the same model1 and model2 model definitions, the syntax would present as such.
# fit an ensemble model with model1 and model2
prepare_stack(
model1,
model2
) %>%
# after evaluating computational considerations,
# fit all members with non-zero stacking coefficients
fit_members()However, for one, this approach introduces yet another computational redundancy; the time to add candidates to a data stack, in some use cases, is not trivial.
The obfuscation of add_candidates and blend_predictions in the prepare_stack syntax introduces a similar computational inconsideration that the stack_models approach did. The synthesis of operations introduced in prepare_stack means that if a practicioner fits the meta-learner and finds the grid search specified to be unsatisfactory, she must perform the add_candidates step again, even if the candidate models are the same.
While add_candidates performs a number of operations, its runtime is roughly equivalent to the runtime for prediction for the supplied model definition(s); add_candidates collects predictions on the validation set from each resampled model and summarizes them to generate the vector of validation set predictions for the candidate member. As was the case in the section above, the computational complexity of this operation depends on the specific candidate model types in question. Even when a model’s time-to-predict scales linearly with the cardinality of a dataset, though, this runtime is not negligible, and ought not be carried out more than once if possible.
To demonstrate this cost in computing time, we’ll turn example modeling objects used in an earlier part of the thesis. (The code to compute these objects is not currently publicly available; I’ll drop a link here when that’s no longer the case.) In that portion, we generated a k-nearest neighbors (knn_res), ordinary least squares (lin_reg_res), and support vector machine (svm_res) model to predict the sale price of homes in Ames, Iowa.
Initially, we compute the time to collect the predictions from each of these model definitions using the system.time function.
time_to_add <- system.time(
ames_st <-
stacks() %>%
add_candidates(knn_res) %>%
add_candidates(lin_reg_res) %>%
add_candidates(svm_res)
)
ames_st## # A data stack with 3 model definitions and 11 candidate members:
## # knn_res: 4 model configurations
## # lin_reg_res: 1 model configuration
## # svm_res: 6 model configurations
## # Outcome: Sale_Price (numeric)time_to_add[["elapsed"]]## [1] 2The time to add these candidate members was 1.6 seconds. Now, evaluating the runtime for fitting the meta-learner for one possible penalty value:
time_to_fit <- system.time(
ames_st <-
ames_st %>%
blend_predictions(penalty = .1)
)
ames_st## ── A stacked ensemble model ─────────────────────────────────────##
## Out of 11 possible candidate members, the ensemble retained 1.
## Penalty: 0.1.
## Mixture: 1.##
## The 1 highest weighted members are:## # A tibble: 1 x 3
## member type weight
## <chr> <chr> <dbl>
## 1 lin_reg_res_1_1 linear_reg 0.371##
## Members have not yet been fitted with `fit_members()`.time_to_fit[["elapsed"]]## [1] 10The time to fit the meta-learner in this case was 9.5 seconds. At first glance, the time to add candidates may seem negligible in comparison, given that it took only 16.9% of the time needed to fit the meta-learner.
However, note that the proposed model stack is being evaluated on only 11 potential members and cross-validation folds of roughly 450 rows. While the computational complexity of adding additional candidates depends on the computational complexity of prediction for a given candidate, the runtime to add n candidates can be reasonably assumed to scale roughly linearly with n. (That is, we assume that a “randomly chosen” statistical model will take just as long to compute predictions as the next.)
On the other hand, in theory, the time to fit an elastic net model scales with the square of the number of predictors (Zou, 2005). However, the implementation of cyclical coordinate descent in fitting the elastic net meta-learner with {glmnet} substantially impacts the computational complexity of this operation (Friedman, 2010). The figure below shows the reality of how {glmnet} fit times scale with the number of predictors. (The source code for generating this figure was originally in the thesis appendix, and will be posted when the full thesis is available.)
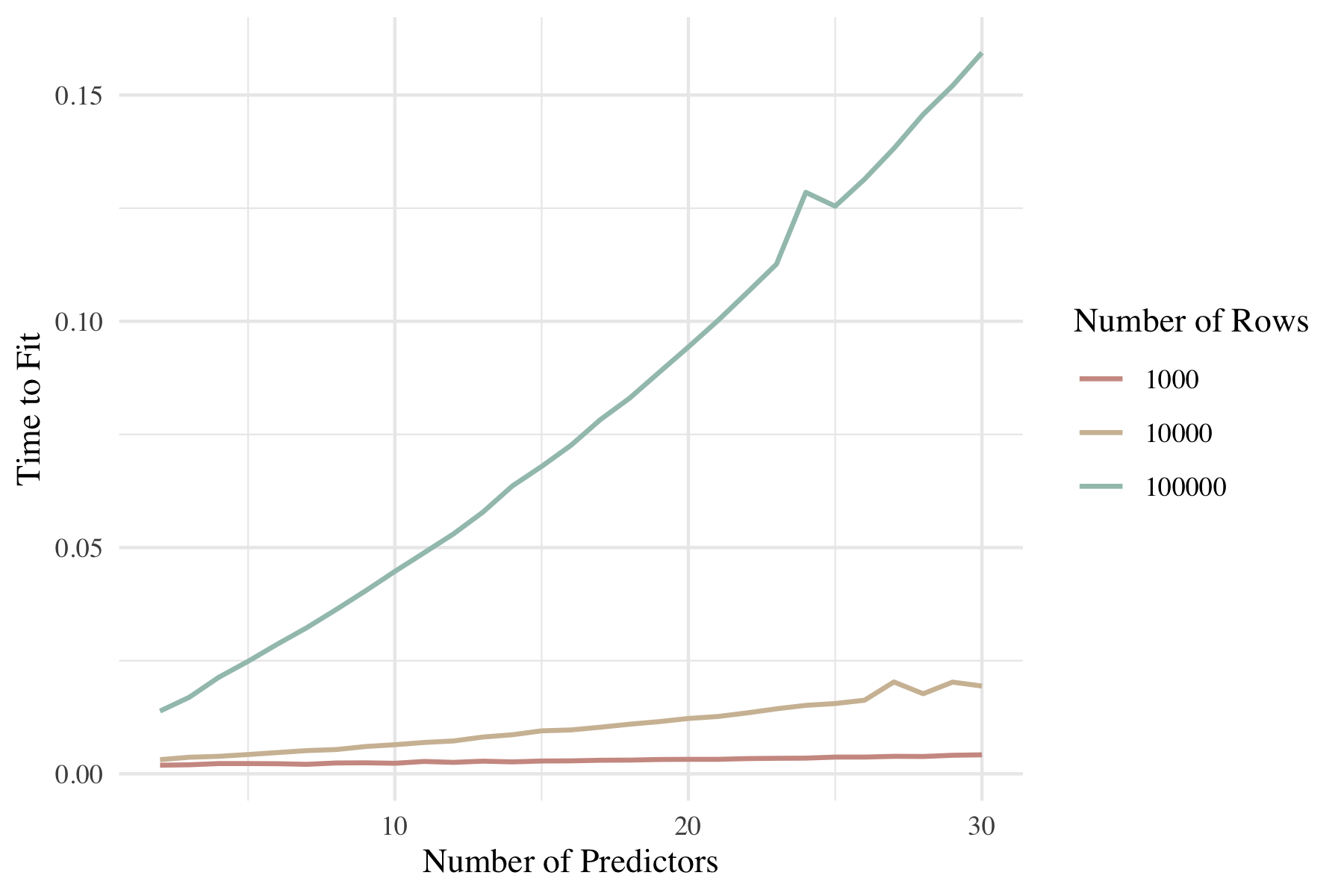
Figure 1: A plot showing the time to fit an elastic net model in seconds, averaged across 30 simulations, as a function of the number of rows and predictors. While the relationship is surely not perflectly linear, it is near so; in most applied use cases, the time to fit the elastic net meta-learner can be reasonably estimated with a linear approximation on the number of predictors.
While the runtime of the elastic net fitting operation does not scale perfectly linearly with the number of predictors, in most applied model stacking settings, a linearity assumption is appropriate for estimating the time to fit such a model. The “predictors,” in the case of fitting the meta-learner, are the candidate model outputs. Thus, while a 16.9% increase seems negligible in the context of this example, that proportion roughly holds for significantly more computationally intensive ensembling use cases. For many applied use cases of model ensembling (i.e. on the scale of 10-100 candidate members being evaluated for training on much larger datasets than in this example), the need to redundantly add candidates each time a practitioner would like to refine her grid search in fitting the meta-learner becomes more cumbersome.
Given this, then, {stacks}’ syntax ought to delineate between the steps of adding candidate models and blending their predictions.
Do you believe in magic?
As a result of the above considerations, we’ll instead consider a syntax with three distinct steps:
- Initialize a stack and add candidate members with
prepare_candidates - Fit the meta-learner on those candidates’ predictions to generate stacking coefficients with
blend_predictions - Fit the candidates with non-zero stacking coefficients on the full training set with
fit_members
Working from the current syntax, such an approach might look something like this:
# initializes a data stack, adds all candidate members,
# and fits the meta-learner on their predictions
prepare_candidates <- function(...) {
stacks() %>%
purrr::reduce(
...,
add_candidates
)
}
# the current blend_predictions function is left as is
blend_predictions <- blend_predictions
# the current fit_members function is left as is
fit_members <- fit_membersWith the same model1 and model2 model definitions, the syntax would present as such.
# add model1 and model2 candidates
prepare_candidates(
model1,
model2
) %>%
# fit the meta-learner
blend_predictions() %>%
# after evaluating relevant computational considerations,
# fit all members with non-zero stacking coefficients
fit_members()To recognize the problem(s) that such a syntax leaves unaddressed, we must look to the intersection of tidy design principles and data pedagogy.
In many ways, the approach to add candidate members implemented in prepare_candidates presents like a “vectorized” alternative to add_candidates. In communities of statistical computing, vectorization is often used colloquially to communicate that a function is able to iteratively perform computations on an input if that input has length greater than one. More exactly, a function \(f\) is vectorized over a vector input \(x\) if and only if \(g_j(f(x)) = f(g_j(x))~\forall~j\), where \(g_j\) takes in some subsettable object \(x\) and outputs the \(j\)-th element. It follows, then, that \(f\) may be vectorized over \(x\) if \(g_j\) is well-defined for all \(~j~\in~ \{1,~2,~...,~\max(\vert x \vert,~ \vert f(x)\vert)\}\), where \(\vert \vert\) denotes the number of subsettable elements indexed by \(j\).
In R, if \(x\) is an S3 object, \(g_j\) can be written as g_j <- function(x) {x[[j]]}. For context, I note some common objects subsettable with this syntax and the results of subsetting them.
data.frame: Subsetting thejth element of a data frame, or its subclasses, returns thejth column of the data frame. For this section,tune_resultsobjects anddata_stacks are notable subclasses of data frames.tune_resultsobjects encapsulate model definitions and do not have a number of columns sensitive to the number of candidate members specified therein.data_stackobjects collate validation set predictions from each candidate member and have a number of columns one greater than the number of candidates in the regression setting, or one greater than the number of candidates \(\times\) number of possible outcomes in the classification setting.list: Subsetting thejth element of a list returns thejth element of the list, which can be an R object with any number of dimensions or class structures. Note thatdata.frames are alistsubclass, though are usually not colloquially referred to as such.- atomic
vector: Subsetting thejth element of an atomic vector returns thejth element of the vector, which must be an atomic element. Note that (non-atomic)lists are vectors, though are usually not colloquially referred to as such.
Addition to one is an example of a vectorized operation.
# construct a subsettable vector x
x <- c(1, 2, 3)
# define a function f
add_one <- function(x) {1 + x}
# check the definition for j = 3
add_one(x[[3]]) == add_one(x)[[3]]## [1] TRUEIn the case of prepare_candidates, then, consider a vector x of two model definitions. a and b are abstracted representations of model definitions specifying one and two candidate members, respectively.
a <- "a model definition specifying one candidate member"
b <- "a model definition specifying two candidate members"
x <- c(a, b)
x## [1] "a model definition specifying one candidate member"
## [2] "a model definition specifying two candidate members"Thus, \(g_j\) is well-defined only for \(j \in \{1,~2\}\) where \(g_1(x) = a\) and \(g_2(x) = b\). Note, though, that we can only subset \(x\) to extract model definitions—candidate members themselves are not subsettable elements of a or b.
This example may present as overly-simplistic, but encapsulates the principal issue with proposing that add_candidates may be vectorizable over model definitions. Regardless of how many candidate members a model definition specifies, its fundamental “elements” (i.e. the results of subsetting the tune_results object) are the same. That is, the length of an tune_results model definition object is not determined by the number of candidate members. In this way, there is no way to “subset out” a specific candidate member from neither a nor b.
If the output of prepare_candidates was also subsettable by model definition, this may not be an issue. However, the output of any call to prepare_candidates is a data_stack object with a number of columns one greater than the number of candidates specified in ..., where the first column always contains the true validation set outcomes from the shared resamples used to define each model definition. The “elements” of this object, then, are the candidate members in question. Model definitions may specify any number of candidate members.
More concretely, let \(f\) be prepare_candidates and \(g_j\) be defined by g_j <- function(x) {x[[j]]}. Then \(f(a)\) is a data frame with two subsettable columns, where \(g_1(f(a))\) returns the true validation set outcomes and \(g_2(f(a))\) returns the validation set predictions for the candidate member specified by a. Similarly, \(g_1(f(b))\) returns the true validation set outcomes, and \(g_2(f(b))\) and \(g_3(f(b))\) return the validation set predictions for the first and second candidate members specified by b, respectively. Finally, \(g_1(f(x))\) again returns the true validation set outcomes, \(g_2(f(x))\) returns the validation set predictions for the candidate member specified by a, and \(g_3(f(x))\) and \(g_4(f(x))\) return the validation set predictions for the first and second candidate members specified by b, respectively.
The prepare_candidates approach, then, is only vectorized in the colloquial sense of the word. I argue, further, that not only is this pseudo-vectorization ultimately not helpful for user experience, but actively detracts from a practitioner’s ability to add candidates in context.
To demonstrate, let’s do something wrong. In addition to the k-nearest neighbors (knn_res), ordinary least squares (lin_reg_res), and support vector machine (svm_res) models from earlier, let’s introduce a neural network model definition as nn_res, and suppose that it was somehow ill-specified for inclusion in an ensemble in its construction.
Both the syntax in question and the current syntax would fail in attempting to add candidates.
# the syntax in question
prepare_candidates(
knn_res,
lin_reg_res,
nn_res,
svm_res
)
# the current syntax
stacks() %>%
add_candidates(knn_res) %>%
add_candidates(lin_reg_res) %>%
add_candidates(nn_res) %>%
add_candidates(svm_res){stacks} may or may not handle the error introduced while adding the neural network candidates gracefully. While it would be somewhat more painful to construct helpful errors from the developer’s perspective in a prepare_candidates-style implementation, this is not my point. Suppose that the clarity of the error—and {stacks}’ gracefulness in handling it—is the same between these two syntax options. What debugging strategies do these syntaxes accommodate?
A notable strategy, and one which is common among many practitioners using tidy package ecosystems, owes itself to the composability design principle of tidy packages. In the current syntax, since discrete operations are separated into discrete calls, a practitioner may iteratively comment out a line of code (and its associated pipe), rerun the code, and check for an error until she has identified the source of the error.
# if an error arose somewhere in this pipeline...
stacks() %>%
add_candidates(knn_res) %>%
add_candidates(lin_reg_res) %>%
add_candidates(nn_res) %>%
add_candidates(svm_res)
# ... one could identify the source by commenting out
# calls to add_candidates in succession, like so
stacks() %>%
add_candidates(knn_res) %>%
add_candidates(lin_reg_res) %>%
add_candidates(nn_res) # %>%
# add_candidates(svm_res)
stacks() %>%
add_candidates(knn_res) %>%
add_candidates(lin_reg_res) # %>%
# add_candidates(nn_res) %>%
# add_candidates(svm_res)Upon the realization that the last iteration of the pipeline runs correctly, the practitioner now knows that the nn_res model definition is the source of the relevant error, and can troubleshoot further.
This debugging strategy is common enough among users of tidy ecosystems that several web extensions and RStudio Add-ins have been developed to accommodate and improve the effectiveness of the strategy, such as Miles McBain’s {breakerofchains} or Nischal Shrestha’s {DataTutor}. Given that the generation of inputs to {stacks} functions requires intimate familiarity with both the {tidyverse} and {tidymodels} ecosystems, accommodating this strategy is surely helpful.
Now that the magic has gone
Given the above discussion, then, we arrive at a syntax that is not far from that ultimately implemented in the package. Transitioning add_candidates from its pseudo-vectorized alternative, we arrive at the following syntax.
# an alternative formulation of add_candidates that can
# initialize a data stack if one is not already present,
# and otherwise performs the functionality of add_candidates
form_candidates <- function(data_stack = NULL, ...) {
if (is.null(data_stack)) {
data_stack <- stacks()
}
data_stack %>%
add_candidates(...)
}
# the current blend_predictions function is left as is
blend_predictions <- blend_predictions
# the current fit_members function is left as is
fit_members <- fit_membersThis syntax is nearly identical to that utilized in the package, with the exception of the coupling of the stacks initialization and add_candidates steps. I refer to this coupling as form_candidates, where the function can initialize a data stack if one is not supplied, and otherwise works in the same way that add_candidates does.
With the same model1 and model2 model definitions, the syntax would present as such.
# add model1 and model2 candidates
form_candidates(model1) %>%
form_candidates(model2)
# fit the meta-learner
blend_predictions() %>%
# after evaluating relevant computational considerations,
# fit all members with non-zero stacking coefficients
fit_members()A ready rebuttal one might have in reaction to my proposal that this syntax is not appropriate is “you chose a bad name for form_candidates!” This argument is correct, and leads to my reasoning well. To name a function, one must articulate what it does. What does form_candidates—or a function by a different name that does the same thing—do? Especially given the argument that add_candidates cannot be properly vectorized, the action that form_candidates performs is dependent on the form of its inputs. I don’t mean this technically, for there are formal mechanisms (that is, object orientation) to accommodate operations whose exact implementation must be sensitive to the form of its input. Rather, colloquially, form_candidates performs two distinct operations on two different types of things, and there are not verbs that can describe the action being carried out insensitively to the form of the input.
- If provided nothing as its first argument,
form_candidatescreates a data stack and then appends the second argument to the data stack. - If provided a data stack as its first argument,
form_candidatesappends the second argument to the data stack provided.
What word can describe creation from nothing and addition to something simultaneously? For this reason, I argue that the form_candidates approach is an overextension of object orientation.
Instead, then, the package ought to delineate between these steps of creating and appending, assigning more appropriate and evocative names to each operation. This first step involves the creation of a minimal instance of a data_stack which can be later appended to and manipulated by other functions in the package. Luckily, users of the {stacks} package have a mental map, formed while learning the APIs of many of {stacks}’ dependencies and otherwise related packages, from which they can draw to understand the appearance and role of such a function. In numerous packages in the {tidyverse}, {tidymodels}, and adjacent ecosystems, a function by the same (or similar) name of the package returns a minimal instance of an object class defined in the package, serving as a starting point for code that will ultimately add to or modify that object. Notable examples include {ggplot2} and {tibble} from the tidyverse, {workflows} and {recipes} from the {tidymodels}, and {data.table} and {gt} elsewhere.
The real magic was the friends we made along the way
And thus, here we are; we’ve landed at the syntax that we ultimately implemented in the package. Maybe you saw that coming. To construct an ensemble using our old friends model1 and model2, we can use the following code.
stacks() %>%
add_candidates(model1) %>%
add_candidates(model2) %>%
blend_predictions() %>%
fit_members()While this syntax is surely less concise than those considered so far, it offers a number of advantages over the one-function stack_models approach:
- The syntax offers moments for pause to a practitioner who would like to evaluate her choice of grid search specification. She need not redundantly perform the steps of adding candidates to a data stack nor fitting candidates on the full training set, both of which are computationally intensive enough to warrant careful consideration.
- The syntax roughly reflects the way these operations would be explained colloquially, and thus owes itself to function and argument names that are coherent and comprehensive. It is for this reason that we did not consider more verbose syntaxes.
- The syntax takes seriously the technical and pedagogical implications of an implementation that presents as vectorized but ultimately promotes a misunderstanding of the form of its inputs.
The real super auto AI machine learning magic truly was the friends we made along the way. Here’s to more keystrokes.