This is the third of four blog posts on the development process of the {stacks} package, excerpted from my Reed senior thesis project Tidy Model Stacking with R.
Part 1: Introduction
Part 2: Splitting Things Up
Part 4: Big Things
Over the course of development of {stacks}, we considered many “trios” of names for the core functions.
The core functions in the trio perform the following operations, respectively:
- Add candidate member models to a data stack, proposing them for inclusion in an ensemble model. This function was ultimately named
add_candidates(). - Fit a “meta-learner” that combines the predictions from each of the candidates members in the data stack. This function was ultimately named
blend_predictions(). - Fit each of the candidate members with nonzero stacking coefficients (i.e. coefficients from the meta-learner, one for each candidate member) on the whole training set. This function was ultimately named
fit_members().
To learn more about how each of these functions are used in practice, check out the Getting Started vignette.
We felt relatively sure that each trio ought to share some sort of basic grammatical structure. For example, each function name could be composed of:
- only a verb, e.g.
add,blend, &fit - a verb and a direct object, e.g.
add_candidates,blend_predictions, &fit_members - a prefix and a verb, e.g.
stack_add,stack_blend, &stack_fit - all three, e.g.
stack_add_candidates,stack_blend_predictions, &stack_fit_members
The verbs and direct objects in question and the meanings they imply, as well, left us with many options to consider. (The name of the package itself going without saying.)
I argue, though, that this question is not only an aesthetic one, but one whose answer implicates a number of technical challenges and implications for data pedagogy. To demonstrate, I will consider a few of the later iterations of these sets of function names. I refer to these sets as “grammars” rather than “syntaxes” (as in the previous blog post) in order to accentuate that I am no longer considering the coarseness with which the requisite operations for fitting an ensemble model are grouped into functions—there will always be three distinct functions in this section—but the names given to each function.
add, blend, & fit
For users of IDEs without auto-complete features (and non-IDE users), there’s much to say for a grammar as concise as add, blend, and fit.
In RStudio, as well as many other popular IDEs, the full names of possible functions, methods, and other objects in the environment will be suggested at the tooltip after typing three or more letters. The extent to which such a feature is helpful, primarily, is a function of how many more keystrokes a function name will require than three.
For R programmers who do not use such an IDE, though, minimizing the number of keystrokes necessary to write code using a given package is surely a helpful thing to keep in mind as a package developer. The number of {stacks} users who do not develop in RStudio may seem small, especially given that {stacks} is situated in the RStudio-funded {tidymodels} package ecosystem. However, I contend that {stacks} ought to be sensitive to the needs of these users, for several reasons. Namely,
- At the time of writing, a significant number of RStudio features are inaccessible for blind developers and data scientists. As such, many blind R developers are not RStudio users, making use of a wide array of alternative development environments. As Jooyoung Seo noted in his rstudio::global(2021) talk, “Data science requires insight, not sight” (Seo, 2021). A positive user experience with {stacks} ought not to require sight as well.
- RStudio-funded open source package developers ought to think carefully about the tension between their obligation to RStudio as a company and the spirit of open source. Is an R software package truly “free and open source” if a positive user experience is contingent upon the usage of a closed-source IDE built by a for-profit company? In reality, there are all sorts of complications to implying such a tension, and many potential conflicts of interest that one might deduce would follow from this relationship do not hold true in practice. (Said more plainly, it’s my experience that RStudio genuinely cares about supporting free and open source software users and developers.) That said, I generally feel R package design can anticipate the addition of RStudio Addins (user-contributed extensions to the IDE) for the improvement of user experience, but ought not admit itself to a poor user experience outside of RStudio due only to inconsiderate API design.
In any case, the inputs to {stacks} functions are the culmination of often hundreds of lines of code. {stacks} is situated in a software ecosystem (the tidymodels) that prioritizes intentionality and decision-making over code brevity. Writing code in such an ecosystem thus relies heavily on IDE tools such as auto-complete (as well as the homegrown {usemodels} tool for generating boilerplate code) to write code. The result is code that is, from one perspective, expressive and principled, and from the other, long. As such, the gains in truncating function names to as few characters as is proposed here might be more easily offset by the challenges such a grammar implies.
Indeed, this grammar introduces several technical challenges. For one, such a grammar does little to clarify the distinction between the blend and fit steps. Fundamentally, both of these steps involve fitting a statistical model—the former step fits the meta-learner model that will combine predictions from each member, while the latter fits the member models whose predictions will be combined by the meta-learner.
Thus, if only one of these methods were to be named fit, the distinction between which of these steps ought to be fit or blend would be arbitrary and likely misleading.
Further, add and fit (and, arguably, any verb with five or fewer characters) are both function names that are useful in numerous data analysis and modeling settings beyond model stacking. Thus, functions with these names are exported in numerous widely used packages, in some cases introducing namespace conflicts. Namespace conflicts arise when two or more packages supply a function—say, add—of the same name, such that the behavior of calling add without explicitly specifying the namespace (i.e. stacks::add) ultimately depends on which package has been loaded more recently. In package development, namespace conflicts ought to be avoided as much as possible.
However, while the behavior of a function likely ought not to depend on the order of recently loaded packages, it could very well be useful for the behavior of a function to depend on the structure of what is passed to it. This is the premise of object-orientated programming, for which the most mainstream implementation in R software is the S3 system.
As an example, if I pass a data_stack object to a function called fit, the most sensical thing to do would probably be to fit the meta-learner that ultimately will inform how to best combine the predictions contained in the data stack. However, this is probably not also the case for a model_stack object. In the case of a model stack, the meta-learner has already been fitted, so a fit function applied to a model_stack probably ought to fit the member models whose predictions will be combined by the meta-learner.
To implement this kind of framework, one could define a generic function, fit, which just looks at the class of what’s passed to it, and then dispatches to the correct method, or implementation of fit as applied to a specific object class. In the case of fit, specifically, the {generics} package supplies a number of helpful function generics, including fit. Thus, to implement this kind of framework in {stacks}, the package would re-export the {generics} package’s fit generic function and then implement fit methods for the data_stack and model_stack classes. Such an implementation would result in {stacks} pipelines appearing something like the following.
stacks() %>%
add(candidate1) %>%
add(candidate2) %>%
fit() %>%
fit()Understanding this code requires a strong understanding of S3 object-orientation, as well its application within the package specifically, in order for a practitioner to know how many times to she ought to call fit and which operations were happening with each call. This need not be a requisite for fitting ensemble models in R. Even then, though, this grammar results in the juxtaposition of an iterative add method, which does not alter the object class, and two fit methods, one of which alters the object class and neither of which can be called iteratively.
One could use two non-fit verbs for these two steps, but our creativity failed us in coming up with appropriate names given that approach.
add_candidates, blend_predictions, & fit_members
While working with a grammar like add_candidates, blend_predictions, & fit_members is surely made easier by an auto-complete feature, it only takes advantage of one of two notable benefits to auto-complete. If a practitioner remembers the name of the function she is planning on using, auto-complete is very much helpful here; after typing the first three characters, the large majority of keystrokes can then be eliminated through the use of the tooltip. However, this grammar does not make effective use of the tooltip in the case that the practitioner does not remember the name of the function she intends to use. Grammars making use of prefixing, where functions with shared functionality are prefixed with the same three (or more) characters, only ask that a practitioner can recall that one prefix in order to see the possible options suggested. In addition to saving keystrokes, then, such grammars can uniquely provide access to short-form, “fly-by” documentation—the grammars discussed in the following two subsections are such examples.
This grammar also introduces a somewhat strange interface in regard to the first argument supplied by the practitioner. Per tidyverse design principles, core functions meant to be called in succession ought to be “pipable”—that is, the first argument (supplied via the {magrittr} pipe %>% operator) to each function ought to be the output of the function called previously. The grammar in consideration presents as such:
stacks() %>%
add_candidates(...) %>%
# ... %>%
blend_predictions() %>%
fit_members()Aligning with this convention results in inconsistent relationships between the direct object in the function name and the argument to which that direct object refers. Walking through the initialization function and three core verbs, consider:
The
stacksinitialization function does not take arguments.The first input to
add_candidatesmust then be the output ofstacks, which is adata_stackobject. Sinceadd_candidatesis called iteratively, the output ofadd_candidatescan also be inputted toadd_candidates. Thus, rather than the candidates, the first argument toadd_candidatesis the object to which the candidates are added, followed by the candidates themselves.The input to
blend_predictionsis the output ofadd_candidates, which is also adata_stackobject. The function does not require any other arguments. Thus, in this case, the direct object (“predictions”) indeed refers to the data stack, which is passed through the pipe operator. Thus, the direct object in this function name refers to a different argument, by position. Further, to be internally consistent withadd_candidates, the first argument is calleddata_stackrather thanpredictions, reflecting the internally defined class of the object supplied as the first argument.The input to
fit_membersis the output ofblend_predictions, which is amodel_stackobject. The function does not accept any other arguments. Thus, in this case, the members referred to in the function name are an element of the first argument, namedmodel_stack, but not the first argument itself. Thus, the direct object in this function name technically does not refer to an argument at all.
One alternative to this set of direct objects would be to refer to the object class (reflected in the argument names) of the inputs, i.e. add_data_stack, blend_data_stack, fit_model_stack. This approach implicates a few challenges, though.
The noted dissonance in argument order—notably, the data stack is not the thing being added—is more immediate.
Suffixing the name of a function with an object class results in a function name that is confusingly similar to that which would result from defining an S3 method that would presumably serve the same purpose. For example, a
fitmethod for amodel_stackobject would be written asfit.model_stack.This grammar could be confusing for a practitioner who does not yet know the underlying object classes (
data_stackandmodel_stack) and the abstract object types they represent (data stacks and model stacks). Notably, it is unclear whether_stackis itself an independent suffix, possibly referring to a noun, verb, or some abstract package identifier. Doesadd_data_stackrefer to adding data to a stack, adding a data stack, stacking data to add to something, or adding data to something in the context of {stacks}? Similar questions could be asked of the two fitting functions.
The contradictions of this sort of grammar may not even occur to some practitioners. “Not that deep,” if you will. For others (including the authors), this grammar has been difficult.
stack_add, stack_blend, & stack_fit
A grammar composed of stack_add, stack_blend, & stack_fit is subject to many of the pitfalls noted for add, blend, & fit. Notably, this grammar does not contribute to distinguishing a necessarily arbitrary delineation between two steps to fitting an ensemble model that are, in essence, model fitting steps.
However, this grammar makes use of both of the potential benefits of auto-complete functionality noted in the above section; not only does the practitioner benefit from auto-complete through a decrease in the number of keystrokes, but she also need only remember one prefix in order to quickly see the names of all functions matching that prefix.
To demonstrate, consider a package {beepbopboop} that implements three operations that can be carried out on two scalars: beep, bop, and boop. The figure below represents the effect of common prefixing and suffixing on the user experience of {beepbopboop} while working in RStudio.
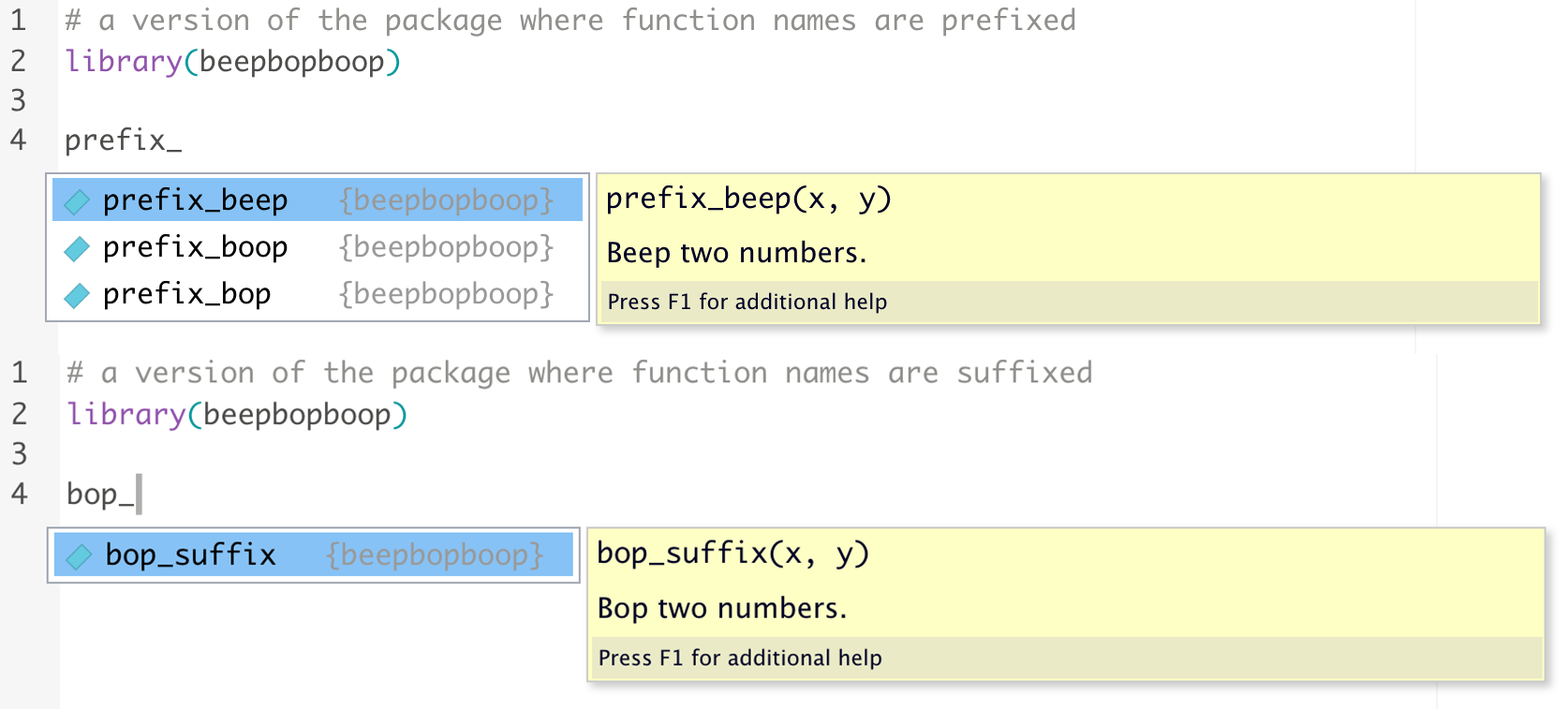
Figure 1: Beginning function and method names with a common prefix allows for usage of auto-complete and the tooltip not only to decrease keystrokes, but also to jog the practitioners’ memory regarding each of the possible operations that can be carried out with a package.
In this more general example, too, we must consider that there are many operations which can be carried out on two scalars. Need a practitioner remember that the beep, bop, and boop methods come from the beepbopboop package specifically? If so, this sort of prefixing/suffixing could be helpful in clarifying the source of the beep, bop, and boop methods. If not, the introduction of package-specific prefixes or suffixes is unnecessarily verbose.
In {stacks}, though, that prefixing comes at a cost. The prefix likely ought to be some iteration of “stack” in order to most memorable in combination with the name of the package. However, placing “stack” at the beginning of function names owes itself to misreading “stack” as a verb. Even then, “stack” is hypersaturated with meanings in the package already—between the name of the package itself, the initialization function, the object classes, and its colloquial usage in “model stacking” and “stacked ensemble learning,” assigning another specific meaning to the word would be ill-considered. This usage also fails to differentiate between model and data stacks, obfuscating the change in object classes after fitting the meta-learner.
As for stack_add_candidates and friends, while this grammar lends itself to both of the benefits of auto-complete mentioned for the current names, it is vulnerable to the same pitfalls of those discussed in the current and prefixed names. For users in IDEs without auto-complete and non-IDE users, this grammar is quite cumbersome.
Where we landed
In short, the following considerations were relevant to ultimately determining the names of the core functions in {stacks}.
How evocative are the function names of the tasks being performed by the functions?
Does the grammar make use of auto-complete to improve access to documentation?
For practitioners in IDEs without auto-complete and non-IDE practitioners, how cumbersome is the grammar to type?
Does the grammar introduce namespace conflicts within relevant package ecosystems? If one or more functions must be S3 methods, are their meanings compatible with the common interpretation of the function?
Is the grammar internally consistent in the manner in which it references function arguments?
If the grammar includes some iteration or abbreviation of “stack,” what part of speech might it be interpreted as? What meanings of the word elsewhere in the package might it obfuscate?
Only some of these questions are relevant to/well-defined for each of the four grammars considered above. Further, none of the grammars in question can provide each of the advantages described above. The table below outlines some of the considerations mentioned in this section.
Grammar =======================================================: add, blend, & fit |
Pros ====================================================: - Concise | Cons | ==========================================================:+ - Does not make use of auto-complete/tooltip - Namespace conflicts likely - Obfuscates two distinct model fitting steps | |
add_candidates, blend_predictions, & fit_members |
|
|
stack_add, stack_blend, & stack_fit |
|
|
The grammar that we landed on is largely an artifact of the ecosystem in which the package is situated, surely with some elements of arbitrary personal preference and random chance.